
Pytorch学习笔记

Pytorch学习笔记
1.验证安装完成
1 | import torch |
2.两个重要函数
1)dir()
1 | dir() |
2)help()
1 | help() |
3.Pytorch加载数据
1)Dataset
提供一种方法获取数据和其label
传入:index
输出:Data,label
2)常见的数据组织形式
1.多种分类数据分列于多个文件夹,这些文件夹名字代表数据的标签
2.包含训练数据文件夹和标签文件夹,与训练数据同名的txt文件中含有数据的label
3.数据的标签体现在数据的文件名上
3)Dataset的使用
1 | from torch.utils.data import Dataset |
1.__Dataset__是一个抽象类,因此数据集类需要继承自该类
1 | class MyDataset(Dataset) |
2.所有子类应当重写__getitem__方法,这个方法是传入index获取其数据和label
1 | class MyDataset(Dataset) |
3.子类也可以重写__len__方法,该方法用于提供数据的长度
1 | class MyDataset(Dataset) |
4.Summery Writer使用
1)SummeryWriter是来自tensorboard模块的可视化工具
使用SummeryWriter时,需要下载tensorboard模块
1 | pip install tensorboard -i https://pypi.tuna.tsinghua.edu.cn/simple |
2)SummeryWriter是一个类,使用时可以传入输出文件夹
1 | writer=SummeryWriter("logs") |
3)SummeryWriter写入单个数据
1 | writer.add_scalar(tag:str,scalar_value,global_step:int) |
4)SummeryWriter写入图片
1 | writer.addimage(tag:str,image,global_step:int,dataformats) |
5.Transforms的使用
1)Transforms是来自pytorchvision包的图片处理工具
1 | from torchvision import transforms |
2)类型转换工具ToTensor
ToTensor是一个类,其中的方法是非静态的,使用时需要实例化
1 | Trans=transforms.ToTensor() |
补充:当类中含有魔术方法__call__时,如果把实例当成函数使用,则会自动调用魔术方法
3)图片拉伸工具Resize
Resize实例化时需要传入想要拉伸的大小,类型时tuple(int,int)
1 | Reshaper=transforms.Resize(size=(300,500)) |
4)图片归一化工具Normalize
Normalize实例化时需要传入均值和标准差,三通道图片的均值和标准差是长度为3的列表
1 | Norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) |
6.处理和使用torchvision数据集
1.示例:使用数据集CIFAR0
1 | import torchvision |
2.使用自定义下载工具下载torchvision数据集
写好数据集名称
1 | torchvision.datasets.CIFAR10() |
使用Crtl+鼠标左键单击进入数据集详情
1 | url = "https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz" |
找到下载链接,用自带的下载工具进行下载(迅雷,IDM,Motrix等)
放入root指定的对应文件夹
1 | train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True) |
3.处理数据
为数据集传入transforms实例即可
1 | from torchvision import transforms |
通过该参数,为数据集指定Transforms,函数会使用实例并且调用魔术方法进行自动处理
注:这也可能是transforms不使用静态方法的有一种考量,为了方便传入实例
7.使用DataLoader配合SummaryWriter().add_images
1.关于DataLoader
Dataloader是来自torch.data.DataLorder的类,其构造函数含有多个参数。
1 | dataset:Dataset类型,需要加载的类 |
2.使用DataLoader
DataLoader在建立之后,可以当成一个迭代器使用,是因为其父类定义了相关方法。
1 | Dta=DataLoader(Dataset,batch_size=25,shuffle=True,drop_last=True) |
3.最终效果
8.继承和使用torch.nn.Module
1.关于torch.nn.Module
torch.nn.Module是nn类的基本骨架,是定义torch神经网络类需要继承的父类。
torch.nn.Module实例化后会存在魔术方法__call__,该方法在调用该实例时会将参数传给forward函数,因此其每一个子类都应该重写forward函数。
2.使用和构建自定义神经网络
1 | from torch.nn import Module |
9.了解和使用卷积和卷积函数torch.nn.functional.conv2d()
1.卷积的概念
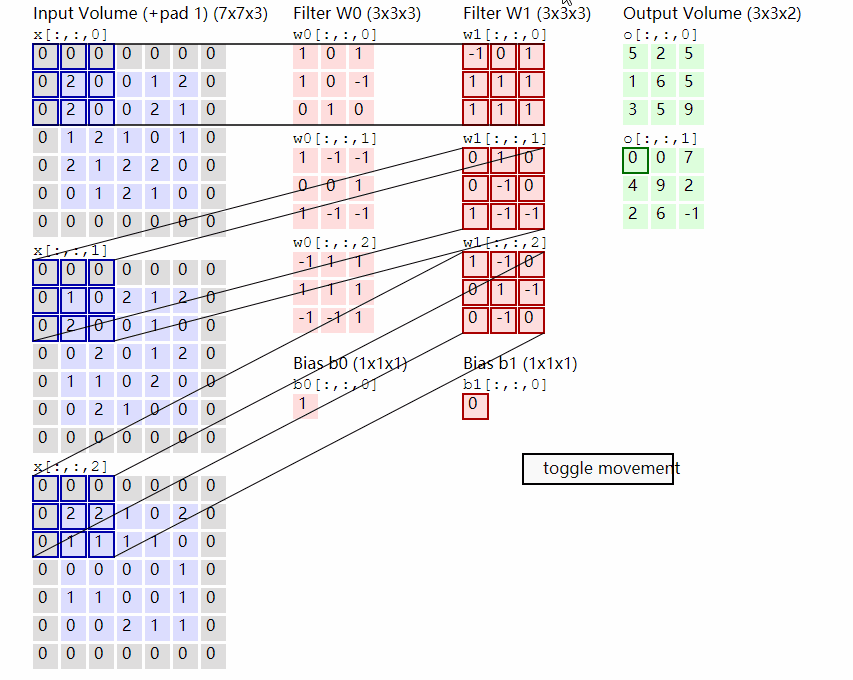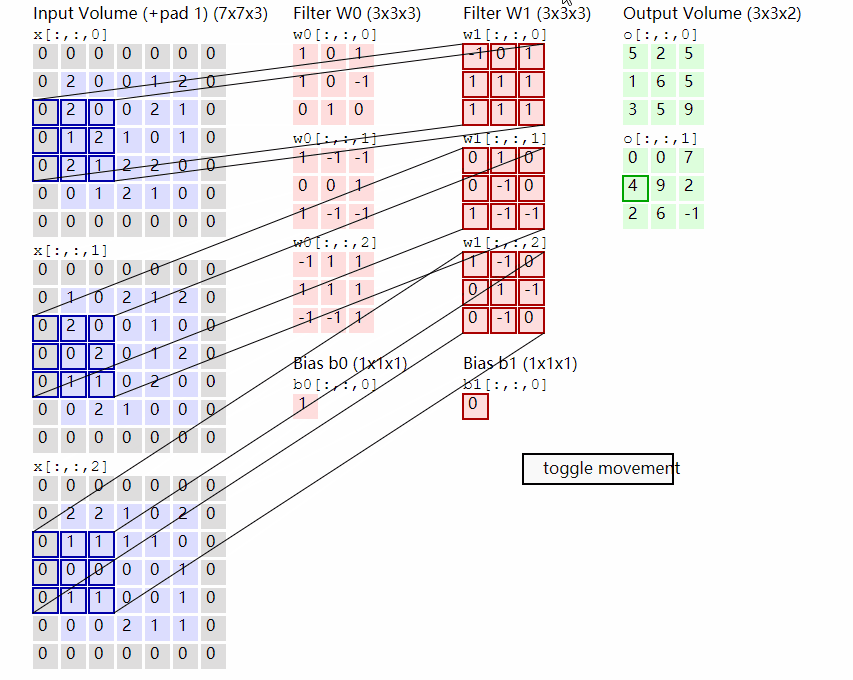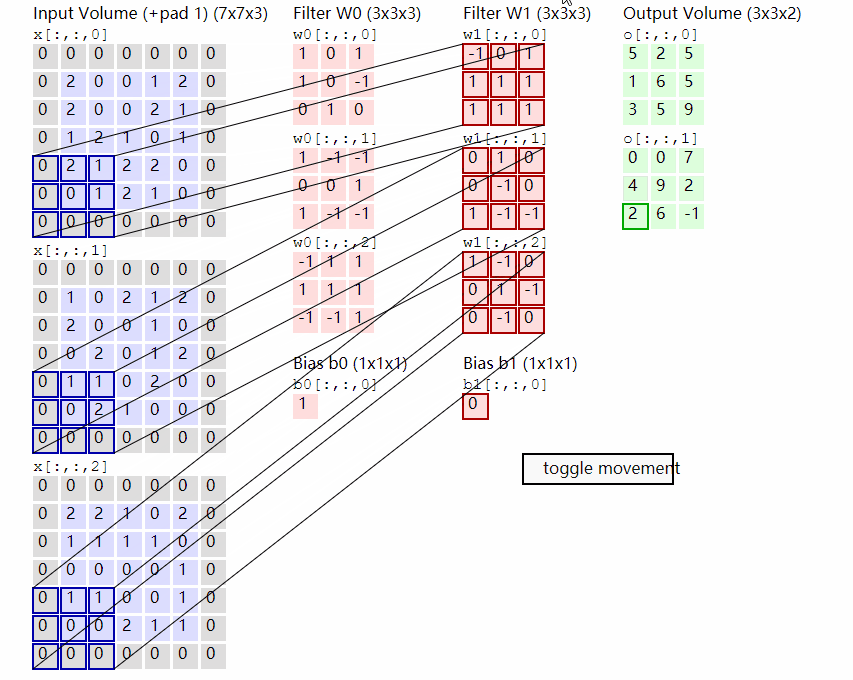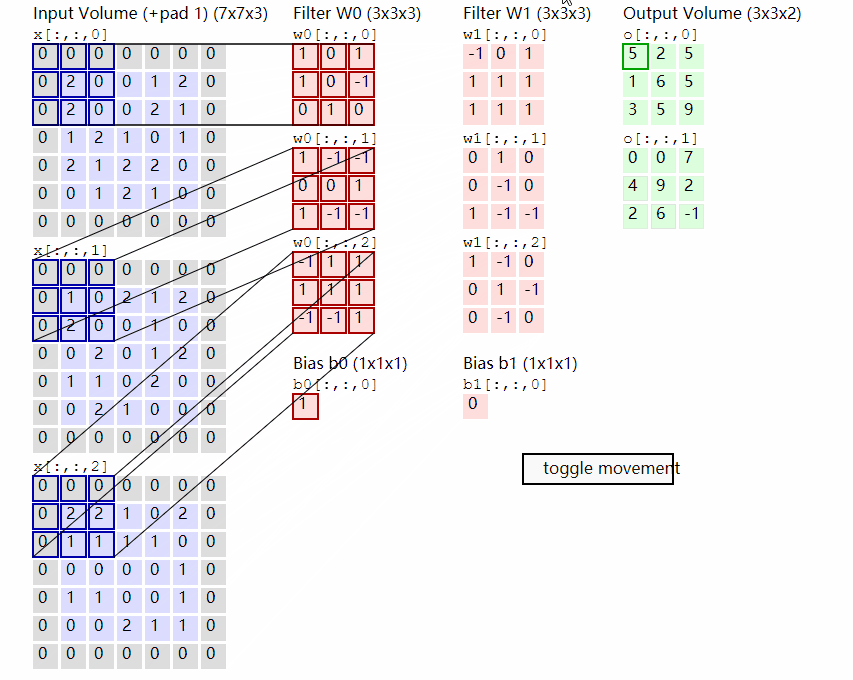
卷积包含两个部分,卷积核和数据。通过使用卷积和对数据的卷积核大小的数据不断做点乘计算,从而生成新的矩阵。
2.使用torch.nn.functional.conv2d
conv族是来自torch.nn.functional类下的方法,包含conv1d,conv2d和conv3d。
使用conv2d时,需要指定twnsor类型的卷积核。
1 | from torch.nn.functional import conv2d |
3.扩展:使用torch.nn.functional.conv2d对灰度图片进行卷积处理
1 | import torchvision |
10.利用Module骨架构建和使用torch.nn.Conv2d类
1.继承自Module的子类在类对象被当作函数使用时会调用子类的forward方法
1 | import torch |
2.初始化和使用Conv2d类
1 | class Myclass(torch.nn.Module): |
3.结合SummaryWriter使用神经网络类
1 | import torch |
11.构建和使用torch.nn.MaxPool2d类对二维tensor数据进行池化
1.关于池化
池化和卷积的操作是类似的,池化拥有一个池化核,通过对池化核对齐的数据取最大值,从而实现最大池化效果。
2.MaxPool2d类
MaxPool3d类的初始化
1 | #kernel_size:int类型,该参数用于指定池化核的大小。 |
初始化类
1 | mypool=torch.nn.MaxPool2d(kernel_size=3) |
3.MaxPool2d类对象call方法只有一个必要参数
1 | img=mypool()(img) |
12.非线性激活类torch.nn.*
1.非线性激活类
非线性激活类有很多种,根据不同的论文研发。
例如:
1 | torch.nn.ReLU() |
这些类在初始化时不需要指定参数,在使用时会对tensor数据类型的每一个数据应用变换。
2.使用方法
1 | from torch import ReLU |
该层的实质是对数据应用一个函数。
13.矩阵展开flatten和线性变换类Linear
1.矩阵展开方法flatten
flatten是能够将高维矩阵按顺序展开成一维列表的方法,其来源是torch,必要参数只有一个,必须是是tensor类型的矩阵。
1 | import torch |
2.实现类似功能的reshape方法
reshape方法也是torch下的矩阵变化方法,当某维度的值为阶数写-1时,会自动推导该维度的阶数。
1 | import torch |
很明显,reshape方法不会改变数据的维数。
3.线性变换类Linear
Linear类是一个和卷积类池化类类似的,初始化的必须参数只有数据大小和需求变换大小的类。
1 | import torch |
通过这种方法,64长度的tensor数据变为了10长度的。
14.使用Sequential类构建神经网络
1.Sequential类是一个可以串联类对象的torch.nn类
Sequential的参数是类的对象,要求该对象继承torch.nn.Module骨架,而且完成了forward函数的重写。
2.Sequential类的使用
例如这张图:

使用Sequential处理构建层
1 | self.prenet=Sequential( |
相当于将所有层整合到了Sequential类中。
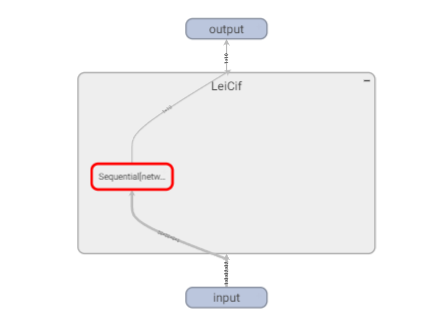
3.SummaryWriter类结合神经网络Sequential类的使用
SummaryWriter类能够和Sequential类结合使用,在tensorboard中打印出模型的具体层数和流程。
1 | writer=SummaryWriter("logs") |
效果如下图
4.Sequential类调试小技巧
编写类ptn,能够打印Sequential计算过程中的数据尺寸,从而实现调试。
1 | class prn(torch.nn.Module): |
15 损失函数的使用
1.注意损失函数的输入输出数据类型
不同的损失函数有着不同的输入输出数据类型。
CrossEntropyLoss类
1 | #CrossEntropyLoss类是一个损失函数类,其初始化时没有必要参数,但是其使用时需要传入各个分类的计算概率和标签。 |
L1Loss类
1 | #CrossEntropyLoss类是一个损失函数类,其初始化时没有必要参数,使用时需要传入结果tensor类和标签tensor类 |
MSELoss类
1 | #CrossEntropyLoss类是一个损失函数类,其初始化时没有必要参数,使用时需要传入结果tensor类和标签tensor类 |
2.反向传播和自动求导机制
损失函数类的backward方法能够对每层神经网络求取梯度,从而为优化器更新提供依据。
1 | LossFunc.backward() |
使用该方法后,torch会对每层网络自动求梯度,并且将梯度累加到Sequential类的Module实例中各层的权重和偏置类的grad属性下,从而使得优化器能够通过step()方法取得这些属性。
16.optmizer的定义和使用
1.torch提供的部分optimizer
1 | #SGD (Stochastic Gradient Descent): 最基础的随机梯度下降法。 |
2.optimizer需要用torch.nn.Module.parameters()和学习率lr来初始化
1 | optim=Adam(MyNet.parameters(),lr=0.01) |
3.optimizer的使用和运作过程
optimizer配合损失函数使用,损失函数LossFunc将自动求导结果在Backward()调用时写入每一层模型的权重和偏置类的grad参数下,当optimizer的step()方法调用时,会获取这些grad梯度以此为依据对权重调整。
由于LossFunc.backward()方法是将梯度累加到网络中,要将这些梯度在每次清零。
17.使用和修改torchvision提供的模型
1.torchvison的模型位于torchvision.models中
比如使用torchvision提供的视觉分类模型vgg19:
1 | import torchvision |
2.为模型加入层
这是表示VGG模型的网络结构。
1 | VGG( |
向vgg加入一个线形层,名字为linear
1 | vgg19.add_module(name="linear",Linear(in_features=1000,out_features=10)) |
向vgg.classifier加入一个线性层,名字为7
1 | vgg19.classifier.add_module(name="7",Linear(in_features=1000,out_features=10)) |
3.替换模型层
虽然向模型加入层很方便,但是有时候新加入的层不一定被模型传播,加入的层就变为没用的层了。
这时我们需要替换模型中有用的层。
比如以图像识别网络ResNet50,其最后的结构是这样的:
1 | (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) |
当我们向modle.resnet其中加入线形层Refc,模型是这样的:
1 | (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) |
但是输出的时候outputs仍然是size(1,1000),说明模型没有经过该层。
那么我们可以使用:
1 | model.fc=Sequential(Linear(in_features=2048,out_features=1000,bias=True), |
16.完整的模型训练套路
1.构建Dataset
Dataset可以使用torchvision提供的数据集
1 | Dataset=torchvision.dataset.CIFAR10(root="./data",download=True,transfer=torchvison.transforms.ToTensor()) |
也可以自己写Dataset数据集,使用散装的图片文件等,那么要重写__getitem__类和可选择重写__len__类
1 | datadir = "./data/train_data_all" |
2.构建DataLoader
dataloader是一个数据迭代器类,要求用一个Dataset对象来初始化,有许多可选参数。
1 | datasets_test = DataLoader(dataset=test_data, batch_size=1, shuffle=True, drop_last=True) |
3.定义模型类
模型类必须是继承自nn.Module的类,为了保证其功能,要将层添加到正向传播方法__forward__中。
1 | class MyModel(nn.Module): |
4.定义损失函数
损失函数使用pytorch提供的损失函数即可。
1 | LossFunc=torch.nn.CrossEntropyLoss() |
在pytorch官方文档选择合适的损失函数。
5.定义优化器
在pytorch官方文档中找到合适的优化器,比如亚当Adam和梯度下降SGD等。
1 | optim=torch.optm.Adam(model_rewriter.parameters()) |
亚当的必要参数只有模型类对象的parameters参数迭代器。学习率会自适应使用。
6.构建训练和测试流程
我们从训练和测试的迭代器中提取数据和标签,用于训练和测试数据。
训练数据:
1 | for data in dataset_train: |
测试数据:
1 | Full_Loss=0 |
这是一个训练轮次的代码,我们需要训练更多轮次从而找到模型的最好表现位置。
在测试数据时可以使用SummeryWriter的add_scalar方法绘制训练损失图,从而达到最好效果。
1 | writer.add_scalar("testloss",scalar_value=Full_Loss,global_step=epoch) |
将轮数写入步数中,从而能够很好展示随着训练进程损失的变化。
- 标题: Pytorch学习笔记
- 作者: 蜀枕清何
- 创建于 : 2025-10-01 12:00:00
- 更新于 : 2025-10-01 22:26:50
- 链接: https://torte.cn/Pytorch/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。